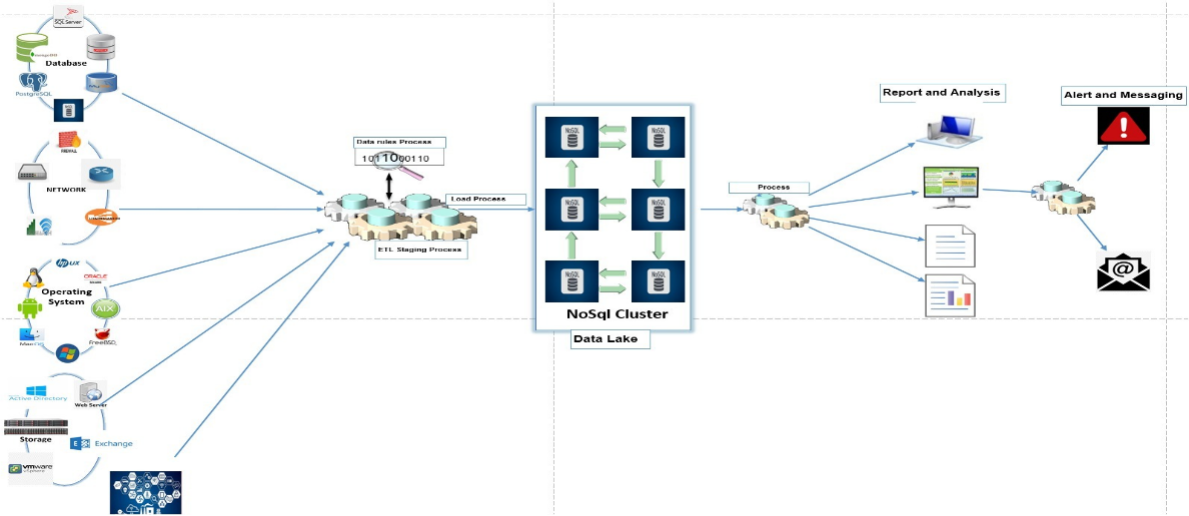
Big Data Platforms, Data Lakes and Lakehouse Architectures
We design and implement scalable big data platforms that can store and process structured, semi-structured and unstructured data at enterprise scale. Our expertise covers classical Hadoop ecosystems as well as modern Data Lake and Lakehouse architectures that unify batch and real-time analytics on a single platform. Key technologies: Apache Hadoop (HDFS, YARN), Hive, HBase, Data Lakes on object storage, Lakehouse frameworks such as Delta Lake, Apache Hudi and Apache Iceberg.
Real-Time Streaming and Event-Driven Processing
We build end-to-end streaming data pipelines that enable real-time analytics, monitoring and event-driven applications. From ingesting high-volume event streams to stateful processing and complex event detection, we design resilient architectures that integrate seamlessly with existing systems. Key technologies: Apache Kafka and Kafka Connect, Kafka Streams, Apache Spark (batch and Structured Streaming), Apache Flink, implemented with Python, Scala and Java.
Search, Log Analytics and Observability (ELK Stack)
We implement search and observability platforms that provide full-text search, log analytics and operational dashboards across heterogeneous systems. These solutions support security monitoring, application performance tracking and business KPIs on a single, unified interface. Key technologies: Elasticsearch for indexing and search, Logstash and Beats for data ingestion, Kibana for interactive dashboards and visualisations.
Performance Analysis and Optimization
We offer specialized services to diagnose and resolve performance bottlenecks in big data environments. This includes analysing cluster resource utilisation, tuning data pipelines, optimising query performance and improving storage layouts to reduce latency and costs. Key techniques and tools: Spark and Flink job profiling, Kafka throughput optimisation, Hadoop/YARN capacity planning, index and shard design in Elasticsearch, OS and network-level tuning.
Technological Upgrade and Modernization
We support organisations in modernising legacy big data stacks, migrating workloads to newer frameworks and, when appropriate, to cloud-native or hybrid architectures. Our focus is on minimising downtime while improving scalability, reliability and maintainability of the overall data platform. Key focus areas: Hadoop-to-Lakehouse migration, on-prem to cloud or hybrid transitions, version upgrades for Kafka, Spark, Flink and ELK, refactoring monolithic ETL jobs into modular, maintainable data pipelines.